


HiddenGnome
-
Posts
162 -
Joined
-
Last visited
Posts posted by HiddenGnome
-
-
Strike-through is not officially supported in Markdown, according to the original specifications which is what our implementation is originally based on. I'm not saying there aren't valid use-cases, only that it is not currently supported.
If you want to read more about it from the author of the spec:
http://daringfireball.net/linked/2015/11/05/markdown-strikethrough-slack
-
The conversion tool does not appear for all unconverted logs, for example:
Hi niraD - I don't see anything in the log that would need to be converted. Is there a particular part of the log that you would expect to be converted?
-
Two bugs actually:
1) The Preformatted Code Block does not work unless the code block is preceded by a line of text and a blank line (in other words, you cannot start a log with a preformatted code block, as when logging something where you want columns of information aligned.
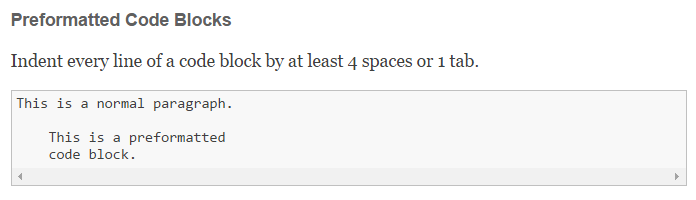
Since the Geocaching.com implementation of Markdown does not permit tables, this is the only way to present, for example, a formatted list of caches in a log.
2) If a log is edited to change the Markdown, the changes are not rendered when the edited log is posted (I discovered this testing for the above bug, and assume it may apply to other or all edited logs).
Thanks for addressing this.
1) Based on the original Markdown spec I would expect that the code blocks need to have a blank line above them (when they are not on the first line) so this seems to be working as intended. However, it does appear that something is not working as expected when adding the code block on the first line. It seems that the preview is showing the code block correctly when it appears on the first line, but the spacing is being lost when the log is posted causing it to no longer render correctly.
2) Is the loss of spacing on the first line code block what you are referring to here?
I will open a ticket for the team to look into why the code block formatting is being lost on the first line. Thanks!
-
I wrote a log a couple of weeks ago in Markdown, which wasn't active then, and it converted itself today ok.
So I added a note in italic to say it had worked and the italic note wasn't in italic. See http://coord.info/GLKX3G1Y
Anyone any idea what is going wrong with italic? Is it me or Groundspeak?
As Target. already mentioned it is necessary to have either a space or what we are calling a "sentence ending" punctuation mark after the closing "*" (the same applies for "_", "__", "**"). The reason is that we are not supporting bold and italic markers inside of a word because there are too many usernames and common expressions that use that pattern. So by following the closing mark with a space or a punctuation mark we can assume that the "*" is not part of the word and properly emphasize it.
Thanks for the great question and for being so forward thinking with your logs!
-
Am I missing something, then? Because when I'm in the latest version of GSAK (851B64) and enter S*W*A*G into a log and do a preview, I see SWA*G as a result.
The API is providing the RAW text so renderings outside of geocaching.com are partner specific. By default, the Markdown specification allows the ability to add bold and italics in the middle of words so the example that you provided would be expected. However, the rendering on geocaching.com has been modified to only support bold and italics surrounding a word in order to avoid unexpected behavior with "*" and "_", especially in the case of events and usernames.
-
How do I get S*W*A*G to look like S*W*A*G? Thanks to whomever replies...
Emphasis marks "*" and "**" will only be interpreted if they surround the word. S*W*A*G will render exactly as written. *S*W*A*G* will render as S*W*A*G (or **S*W*A*G** as S*W*A*G)
-
I am still reading through the various ideas and feedback, but I want to thank everyone who is contributing to the discussion. In order to have a conversation we need a place to begin which is why we wanted to let players know well in advance.
-
Ok, so if I read this right, when a new log is posted it should be sanitized for acceptable content - the system's HTML sanitization script is too old and insufficient to provide a sufficiently secure algorithm (moving forward and for legacy content), and your old implementation of BBCode has known and unfixable security flaws and is too complex to swap out with a newer implementation? (I don't know what "brittle" means)
The code that is currently used to sanitize HTML and render BBCode has become the equivalent of Frankenstein's monster over the years with new "features" or bandaids being bolted on. One of the biggest factors that go into making the code "brittle" is the fact that there are no regression tests around this functionality. For anyone that doesn't know, a regression test is helpful because it allows you to make changes, run your tests and make sure that you haven't broken your existing functionality. Without that in place we are blind and have to rely on manual testing which is time consuming and prone to mistakes. This is why there are occasionally bugs introduced to the website when seemingly unrelated changes are deployed. Our goal is to slowly (because there is too much code to do it quickly) rewrite sections/areas of code, surrounded by a full test suite so that future changes can be made quickly and with confidence that nothing has be unintentionally broken. So to your other comment about it being "module" - I completely agree that it should be, but the current implementation is not.
Challenging the claim that it's not trivial (and supporting with practical suggestions) is, well, precisely what we've done for you
The act of challenging the idea that maintaining multiple rendering paths adds complexity and hinders maintainability does not change the fact that it is not trivial. There have been several proposals about how this could be accomplished and I won't discredit them as they are technical solutions that would accomplish the desired effect of maintaining multiple rendering options, but at the end of the day each and every one will add to the complexity and reduce the maintainability of the system while potentially continuing to allow security vulnerabilities.
This is why the suggestion was made to have an asynchronous bot that runs at low traffic times to analyze and deal with legacy logs as long as any exist which haven't yet been updated. It's fundamentally dynamic in that you can tell it to do 100 at a time or 5000, to work at whatever speed has an imperceptable impact, whether it takes days to get through the database or monthsYou make a good point here. The main issue I was trying to raise was that whether we update 10 logs at a time or 10 million we are still relying on an algorithm to decipher the content of a log in an automated manner which is prone to errors when you consider the number of permutations that exist across 1 billion logs.
-
I will try to answer these where I can.
Will inserting a pure link like www.geocaching.com be treated like now, and be shown as clickable (visit link)? Or will users really have to go back and write "[some text](" before and ")" after a link?
We are adding logic so that URLs will be auto-linked without needing to reformat the URL into Markdown syntax, but I would recommend using the Markdown format after the switchover.
Will it be possible to use something comparable to <s> / ?
I believe you are referring to the strike-through. The Markdown standard does not support strike-through so out of the box it will not be implemented on day one, but we are always open to feedback and feature requests.
# and ##: Will there be really an extra rule compared to Markdown and # and ## only interpreted as header if the line is also ending with a #, or all lines starting with # or ## etc.? Millions of logs would be affected.
This was a large concern that was raised and we are modifying the rule to require a header to begin and end with a #.
# this is not a header
## this is a header ##
Lines starting with numbers, followed by dots (german way to say first, second ...): Always interpreted as ordered list, so other numbers than 2. in the second paragraph/line and 3. in the third paragraph/line will be 'overwritten' on the website?
You have described this accurately.
Lines starting with > (meant as more than): Interpreted as 'quote' and not showing the > anymore?
This will render as a quote unless the '>' is escaped '\>'
Lines starting with *** or ___ or * * *: interpreted like <hr>?
Lines starting with *** or ___ will render normal as long as there is other text on the same line.
Lines starting with * * * will render the first * as a bullet point and the remaining 2 * normally.
Lines starting with + or - or *: interpreted as unordered lists?
If there is a space between the +, - or * and then next character then the line will render as an unordered list. If there is no space then the line will render as before, e.g. "+123"
Lines starting with four or more blanks: Interpreted as 'Code'?
Yes.
And the wide field of emphasis: Will * and _ work as described "Emphasis can be used in the middle of a word" which will alter all usernames containing more than one _ or *, which would also affect usernames like yes_no_maybe, or will only usernames like *Eisbär* and _law_ be affected? Or will usernames like Alter_Fuchs also be affected if an opening or closing _ coincidentally happens to stand nearby?
*text* and _text_ will render as italic
**text** and __text__ will render as bold
Emphasis marks that are in the middle of words or "near" words will not change the rendering.
Alter_Fuchs = Alter_Fuchs
Alter_Fuchs _test = Alter_Fuchs _test
Emphasis marks that do not match will be rendered as written
*text_ = *text_
__text** = __text**
-
Hello everyone! There has been a lot of talk and there are many questions about the changeover to Markdown. I am one of the developers on this project and I will try to provide some insights into the decisions that were made as well as correct the misconceptions that are swirling around this topic.
First and foremost this change, as with every change we make, has no ulterior motive or malicious intent. There is an understanding that change is disruptive and usually ill-received by some, but we are not making changes simply for the sake of change. There is a method to the (perceived) madness and we believe that we are moving towards a game that is better for everyone.
Historically the geocache and trackable logs are nearly unfiltered HTML. We began working on this change because anytime that user generated HTML is involved you open your website and users to security vulnerabilities and closing those down is a top priority. This leads directly into why we are not supporting legacy HTML logs; if we allow older logs to continue rendering HTML then any logs that include security vulnerabilities would still be active which goes against the core reason for making this change in the first place. In order to properly secure the website so it cannot be used as a portal for malicious attack it was deemed necessary to remove the rendering of all user generated HTML in the logs.
HTML is a security issue, so why aren't we going to support BBCode going forward?
BBCode is also a security vulnerability because it ultimately generates HTML that can contain its own vulnerabilities. Our implementation of BBCode in geocache and trackable logs is old and brittle and would need to be completely replaced in order to account for this. With this in mind we decided to look at our HTML rendering engine from a holistic perspective. Markdown and BBCode are "competing" standards that provide a similar set of functionality. However, despite BBCode being around longer, Markdown has emerged as the favorite between the two standards and many people find that Markdown is an easier standard to understand (although I appreciate that this can be subjective). The decision was made not to support two competing standards in our code base and because BBCode is being broadly phased out elsewhere we made the decision to remove support for BBCode. Now, there have been comments that it would be trivial to allow the rendering of both standards by adding a flag or switching based on the log date. I would challenge anyone who claims that maintaining duplicate code paths in a legacy system is a trivial task with no impact on future development or peformance.
If we aren't going to support BBCode, why not convert the BBCode to Markdown?
When you add up geocache and trackable logs we are dealing with over 1 billion records, ranging from 1 character to thousands of characters in length. The type of conversion that is required is difficult to perform in an automated manner because we will need to touch every single log. No query can reliably filter down the number of logs so we need to pull them all back. When dealing with that many logs we cannot account for every permutation in the logs which means that either logs will be missed or worse (and more likely) logs will be incorrectly converted. As a general rule we err on the side of avoiding permanent data loss.
It has been pointed out that logs that were written before Markdown might be converted inadvertently. It is true that there may be cases where plain text gets rendered by Markdown incorrectly. We do not have the concept of plain text vs HTML logs so everything is rendered as if it might contain Markdown. We are working to account for this in advance and we believe that any remaining cases will be minimal in number and impact. Going forward the benefit of moving towards a simplified standard will increase the quality of logs by providing the tools to better express meaning and context. Another benefit is that unlike HTML and BBCode, Markdown is more human readable and works cross platform so that all users can share the same experience.
I'm sure I have left some questions unanswered and there are still people that are unconvinced about this change, but please know that the change is made with good intentions and we are continuing to work towards a smooth transition. Also, just know that we are reading the forums and taking notes of constructive opinions in the various threads on the topic.
-
Thank you to everyone who provided their feedback and to the OP for highlighting an area that we can improve. We are looking into ways to improve the error message in order to provide more context when you respond to a conversation that you are not a part of. This can sometimes happen when you have multiple email addresses coming into the same inbox and your "reply" email address does not match the primary email address of your geocaching account.
Release Notes (Website: Markdown conversion tool) - February 9, 2016
in Geocaching HQ communications
Posted
Hi walter1 - we will definitely have a look at removing that trailing space in the converter. Thank you for reporting the issue.